# 垃圾回收
在JavaScript中,数据类型分为两类,简单类型和引用类型,对于简单类型,内存是保存在栈(stack)空间中,复杂数据类型,内存是保存在堆(heap)空间中。
- 基本类型:这些类型在内存中分别占有固定大小的空间,他们的值保存在栈空间,我们通过按值来访问的
- 引用类型:引用类型,值大小不固定,栈内存中存放地址指向堆内存中的对象。是按引用访问的。
而对于栈的内存空间,只保存简单数据类型的内存,由操作系统自动分配和自动释放。而堆空间中的内存,由于大小不固定,系统无法无法进行自动释放,这个时候就需要JS引擎来手动的释放这些内存。
JavaScript 是使用垃圾回收的语言,也就是说执行环境负责在代码执行时管理内存。通过自动内存管理实现内存分配和闲置资源回收。
基本思路很简单:确定哪个变量不会再使用,然后释放它占用的内存。这个过程是周期性的,即垃圾回收程序每隔一定时间(或者说在代码执行过程中某个预定的收集时间)就会自动运行。
# 1、标记清理
JavaScript 最常用的垃圾回收策略是标记清理(mark-and-sweep)。到目前为止的大多数浏览器的 JavaScript 引擎 都在采用标记清除算法,只是各大浏览器厂商还对此算法进行了优化加工,且不同浏览器的 JavaScript 引擎 在运行垃圾回收的频率上有所差异。
此算法分为 标记 和 清除 两个阶段,标记阶段即为所有活动对象做上标记,清除阶段则把没有标记(也就是非活动对象)销毁。
给变量加标记的方式有很多种。比如,当变量进入上下文时,反转某一位;或者可以维护“在上下文中”和“不在上下文中”两个变量列表,可以把变量从一个列表转移到另一个列表。标记过程的实现并不重要,关键是策略。
(1)优点
标记清除的优点只有一个,那就是实现比较简单,打标记也无非打与不打两种情况,这使得一位二进制位(0和1)就可以为其标记,非常简单。
(2)缺点
标记清除有一个很大的缺点,就是在清除之后,剩余的对象内存位置是不变的,也会导致空闲内存空间是不连续的,出现了 内存碎片(如下图),并且由于剩余空闲内存不是一整块,它是由不同大小内存组成的内存列表,这就牵扯出了内存分配的问题。
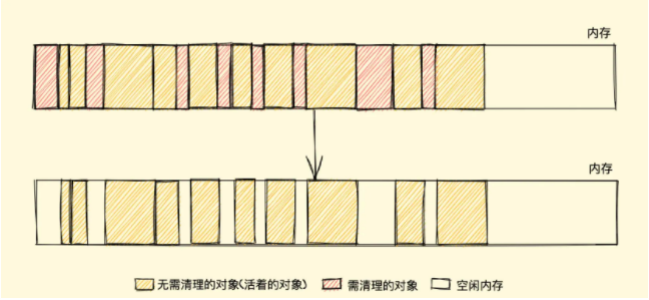
假设我们新建对象分配内存时需要大小为 size,由于空闲内存是间断的、不连续的,则需要对空闲内存列表进行一次单向遍历找出大于等于 size 的块才能为其分配(如下图)
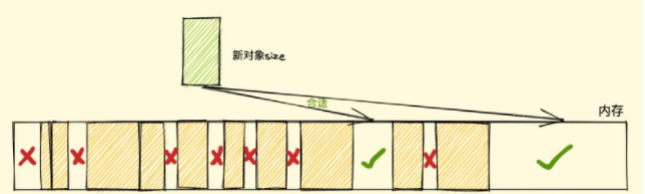
那如何找到合适的块呢?我们可以采取下面三种分配策略:
- First-fit,找到大于等于 size 的块立即返回
- Best-fit,遍历整个空闲列表,返回大于等于 size 的最小分块
- Worst-fit,遍历整个空闲列表,找到最大的分块,然后切成两部分,一部分 size 大小,并将该部分返回
这三种策略里面 Worst-fit 的空间利用率看起来是最合理,但实际上切分之后会造成更多的小块,形成内存碎片,所以不推荐使用,对于 First-fit 和 Best-fit 来说,考虑到分配的速度和效率 First-fit 是更为明智的选择。
综上所述,标记清除有两个很明显的缺点:
内存碎片化,空闲内存块是不连续的,容易出现很多空闲内存块,还可能会出现分配所需内存过大的对象时找不到合适的块
分配速度慢,因为即便是使用 First-fit 策略,其操作仍是一个 O(n) 的操作,最坏情况是每次都要遍历到最后,同时因为碎片化,大对象的分配效率会更慢
# 2、标记整理
标记清除的缺点在于清除之后剩余的对象位置不变而导致的空闲内存不连续,所以只要解决这一点,两个缺点都可以完美解决了。
而 标记整理(mark-and-compact)就可以有效地解决,它的标记阶段和标记清除算法没有什么不同,只是标记结束后,标记整理算法会将活着的对象(即不需要清理的对象)向内存的一端移动,最后清理掉边界的内存(如下图):
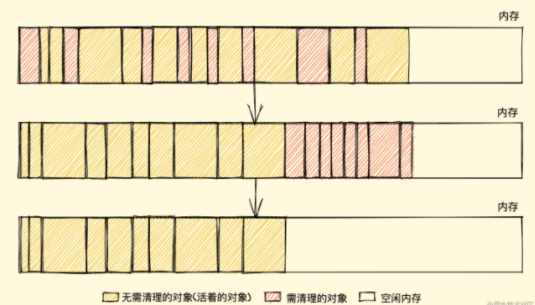
# 3、引用计数
引用计数(reference counting),这其实是早先的一种垃圾回收算法,它把 对象是否不再需要 简化定义为 对象有没有其他对象引用到它,如果没有引用指向该对象(零引用),对象将被垃圾回收机制回收,目前很少使用这种算法了。
它的策略是跟踪记录每个变量值被使用的次数。
- 当声明了一个变量并且将一个引用类型赋值给该变量的时候这个值的引用次数就为 1
- 如果同一个值又被赋给另一个变量,那么引用数加 1
- 如果该变量的值被其他的值覆盖了,则引用次数减 1
- 当这个值的引用次数变为 0 的时候,说明没有变量在使用,这个值没法被访问了,回收空间,垃圾回收器会在运行的时候清理掉引用次数为 0 的值占用的内存
let a = new Object() // 此对象的引用计数为 1(a引用)
let b = a // 此对象的引用计数是 2(a,b引用)
a = null // 此对象的引用计数为 1(b引用)
b = null // 此对象的引用计数为 0(无引用)
... // GC 回收此对象
2
3
4
5
不过在引用计数这种算法出现没多久,就遇到了一个很严重的问题——循环引用,即对象 A 有一个指针指向对象 B,而对象 B 也引用了对象 A ,如下面这个例子
function test() {
let a = new Object();
let b = new Object();
a.b = b;
b.a = a;
}
2
3
4
5
6
如上所示,对象 a 和 b 通过各自的属性相互引用着,按照上文的引用计数策略,它们的引用数量都是 2,但是,在函数 test 执行完成之后,对象 a 和 b 是要被清理的,但使用引用计数则不会被清理,因为它们的引用数量不会变成 0,假如此函数在程序中被多次调用,那么就会造成大量的内存不会被释放。
我们再用标记清除的角度看一下,当函数结束后,两个对象都不在作用域中,a 和 b 都会被当作非活动对象来清除掉,相比之下,引用计数则不会释放,也就会造成大量无用内存占用,这也是后来放弃引用计数,使用标记清除的原因之一。
(1)优点
引用计数算法的优点我们对比标记清除来看就会清晰很多,首先引用计数在引用值为 0 时,也就是在变成垃圾的那一刻就会被回收,所以它可以立即回收垃圾。
而标记清除算法需要每隔一段时间进行一次,那在应用程序(JS脚本)运行过程中线程就必须要暂停去执行一段时间的 GC,另外,标记清除算法需要遍历堆里的活动以及非活动对象来清除,而引用计数则只需要在引用时计数就可以了。
(2)缺点
引用计数的缺点想必大家也都很明朗了,首先它需要一个计数器,而此计数器需要占很大的位置,因为我们也不知道被引用数量的上限,还有就是无法解决循环引用无法回收的问题,这也是最严重的。
# 4、V8的垃圾回收
V8采用分代式垃圾回收机制,将堆内存分为新生代和老生代两区域,采用不同的垃圾回收器也就是不同的策略管理垃圾回收。限制内存的使用(64位约1.4G/1464MB , 32位约0.7G/732MB)
新生代的对象为存活时间较短的对象,简单来说就是新产生的对象,通常只支持 1~8M 的容量,而老生代的对象为存活事件较长或常驻内存的对象,简单来说就是经历过新生代垃圾回收后还存活下来的对象,容量通常比较大。
V8 整个堆内存的大小就等于新生代加上老生代的内存(如下图)
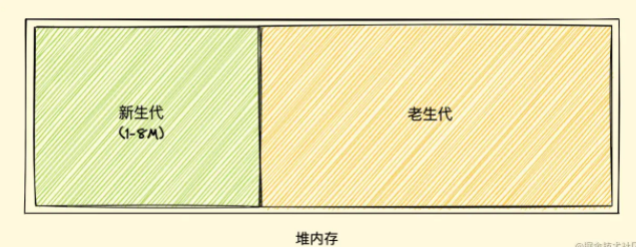
对于新老两块内存区域的垃圾回收,V8 采用了两个垃圾回收器来管控,我们暂且将管理新生代的垃圾回收器叫做新生代垃圾回收器,同样的,我们称管理老生代的垃圾回收器叫做老生代垃圾回收器
# 4.1 新生代垃圾回收
新生代对象是通过一个名为 Scavenge 的算法进行垃圾回收,在 Scavenge 算法 的具体实现中,主要采用了一种复制式的方法即 Cheney 算法,将堆内存一分为二,一个是处于使用状态的空间我们暂且称之为使用区,一个是处于闲置状态的空间我们称之为空闲区,如下图所示:
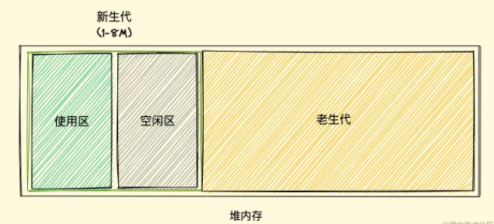
新加入的对象都会存放到使用区,当使用区快被写满时,就需要执行一次垃圾清理操作。
当开始进行垃圾回收时,新生代垃圾回收器会对使用区中的活动对象做标记,标记完成之后将使用区的活动对象复制进空闲区并进行排序,随后进入垃圾清理阶段,即将非活动对象占用的空间清理掉。
最后进行角色互换,把原来的使用区变成空闲区,把原来的空闲区变成使用区。
当一个对象经过多次复制后依然存活,它将会被认为是生命周期较长的对象,随后会被移动到老生代中,采用老生代的垃圾回收策略进行管理。
另外还有一种情况,如果复制一个对象到空闲区时,空闲区空间占用超过了 25%,那么这个对象会被直接晋升到老生代空间中,设置为 25% 的比例的原因是,当完成 Scavenge 回收后,空闲区将翻转成使用区,继续进行对象内存的分配,若占比过大,将会影响后续内存分配。
# 4.2 老生代垃圾回收
相比于新生代,老生代的垃圾回收就比较容易理解了,上面我们说过,对于大多数占用空间大、存活时间长的对象会被分配到老生代里,因为老生代中的对象通常比较大,如果再如新生代一般分区然后复制来复制去就会非常耗时,从而导致回收执行效率不高,所以老生代垃圾回收器来管理其垃圾回收执行,它的整个流程就采用的就是上文所说的标记清除算法了。
# 5、内存管理
将内存占用量保持在一个较小的值可以让页面性能更好。优化内存占用的最佳手段就是保证在执行代码时只保存必要的数据。如果数据不再必要,那么把它设置为 null,从而释放其引用。这也可以叫作解除引用。这个建议最适合全局变量和全局对象的属性。局部变量在超出作用域后会被自动解除引用
(1)通过 const 和 let 声明提升性能
ES6 增加这两个关键字不仅有助于改善代码风格,而且同样有助于改进垃圾回收的过程。因为 const 和 let 都以块(而非函数)为作用域,所以相比于使用 var,使用这两个新关键字可能会更早地让垃圾回收程序介入,尽早回收应该回收的内存。在块作用域比函数作用域更早终止的情况下,这就有可能发生。
(2)隐藏类和删除操作
V8 在将解释后的 JavaScript 代码编译为实际的机器码时会利用“隐藏类”。如果你的代码非常注重性能,那么这一点可能对你很重要。
运行期间,V8 会将创建的对象与隐藏类关联起来,以跟踪它们的属性特征。能够共享相同隐藏类的对象性能会更好,V8 会针对这种情况进行优化,但不一定总能够做到。
function Article() {
this.title = 'Inauguration Ceremony Features Kazoo Band';
}
let a1 = new Article();
let a2 = new Article();
2
3
4
5
V8 会在后台配置,让这两个类实例共享相同的隐藏类,因为这两个实例共享同一个构造函数和原型。假设之后又添加了下面这行代码:
a2.author = 'Jake';
此时两个 Article 实例就会对应两个不同的隐藏类。根据这种操作的频率和隐藏类的大小,这有可能对性能产生明显影响。
当然,解决方案就是避免 JavaScript 的“先创建再补充”(ready-fire-aim)式的动态属性赋值,并在构造函数中一次性声明所有属性,如下所示:
function Article(opt_author) {
this.title = 'Inauguration Ceremony Features Kazoo Band';
this.author = opt_author;
}
let a1 = new Article();
let a2 = new Article('Jake');
2
3
4
5
6
共享一个隐藏类,可以带来潜在的性能提升。不过要记住,使用 delete 关键字会导致生成相同的隐藏类片段。
function Article() {
this.title = 'Inauguration Ceremony Features Kazoo Band';
this.author = 'Jake';
}
let a1 = new Article();
let a2 = new Article();
delete a1.author;
2
3
4
5
6
7
在代码结束后,即使两个实例使用了同一个构造函数,它们也不再共享一个隐藏类。动态删除属性与动态添加属性导致的后果一样。最佳实践是把不想要的属性设置为 null。这样可以保持隐藏类不变和继续共享,同时也能达到删除引用值供垃圾回收程序回收的效果。
function Article() {
this.title = 'Inauguration Ceremony Features Kazoo Band';
this.author = 'Jake';
}
let a1 = new Article();
let a2 = new Article();
a1.author = null;
2
3
4
5
6
7